Generative AI is evolving fast — and cloud platforms are at the heart of it.
From hosting large language models (LLMs) to scaling inference securely, architects and engineers are expected to understand how all the moving parts come together.
I’ve simplified this into a visual mind map — 6 core building blocks + 6 peripheral concepts that every cloud professional should know when working with GenAI workloads.
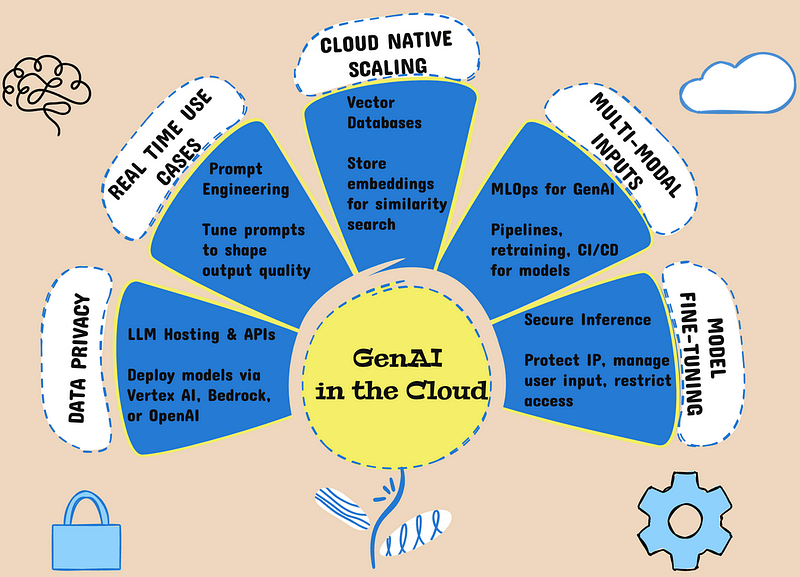
A high-level visual map of GenAI in the cloud — from prompt engineering to secure inference
Breakdown of the 6 Core Pillars:
Prompt Engineering
Fine-tune how your models behave by crafting clear, specific prompts. This skill directly impacts model quality, latency, and cost — especially in inference-heavy applications.
Why it matters: Better prompts → fewer hallucinations → less waste in compute and downstream processing.
LLM Hosting & APIs
Host large models using:
- Google’s Vertex AI PaLM or Gemini
- AWS Bedrock
- Azure’s OpenAI service
- Or directly via OpenAI, Anthropic, etc.
Why it matters: Choosing the right platform impacts latency, pricing, regional compliance, and ecosystem fit.
Vector Databases
Used to store embeddings for similarity search in retrieval-augmented generation (RAG) architectures.
Popular tools include:
- Pinecone
- Weaviate
- ChromaDB
- Vertex AI Matching Engine
Why it matters: Vectors power semantic search, RAG, chat-with-your-docs, and memory in LLMs.
MLOps for GenAI
Traditional MLOps meets GenAI:
- Pipeline orchestration
- Retraining workflows
- Deployment automation
- Versioning of prompts, models, and embeddings
Why it matters: GenAI models change fast — infra needs to be versioned, traceable, and secure.
Secure Inference
Protect sensitive data during inference:
- Sanitize input to prevent prompt injection
- Restrict outputs (e.g., via content filters)
- Use IAM to control who accesses what models
Why it matters: LLMs can leak sensitive data or be exploited if left unchecked.
Cloud-Native Scaling
GenAI workloads spike unpredictably. Autoscaling, serverless endpoints, and on-demand GPUs/TPUs make your architecture resilient and efficient.
Why it matters: GenAI adoption grows → infra must scale without surprise bills or throttling.
Conclusion
Generative AI is not a siloed tool — it’s a cloud-native architecture challenge. From prompt to inference, every step involves security, scale, and strategic tooling. This visual is a guide, not a checklist. Start with one spoke — build from there.
Visualized and written by Akhil Mohan — Cloud Architect at Google, simplifying AI + cloud architecture for everyone.