The “Dump and Pray” Era
We are currently living through a hardware arms race. Gemini 1.5 Pro gives us 2 million tokens. Claude 3.5 supports massive context. The prevailing wisdom in the developer community has become lazy: “Why optimize? Just dump the entire codebase, the documentation, and the JIRA history into the prompt window and let the model figure it out.”
It feels like magic. Until it isn’t.
If you have tried the “dump and pray” method, you know the reality. The model hallucinates details. It forgets instructions buried in the middle of the text. It gets confused by conflicting file versions.
This is what researchers call the “Lost in the Middle” phenomenon. LLMs are brilliant at retrieving information from the start and end of a prompt, but they suffer from severe attention decay in the messy middle.
More context isn’t the solution. In fact, without structure, more context is just more noise.
We don’t need larger windows. We need Context Engineering.
The Shift: From Prompt Writer to Context Architect
Prompt Engineering is about optimizing words. Context Engineering is about optimizing the environment.
Think of your AI not as a genius that needs a better question, but as a brilliant new employee. If you hand that employee a disorganized pile of 5,000 unlabelled documents on their first day, they will fail. If you hand them a curated handbook, a specific file for the task at hand, and a clear set of rules, they will succeed.
To build reliable AI agents, we need to stop treating context as a “bin” and start treating it as a Engine.
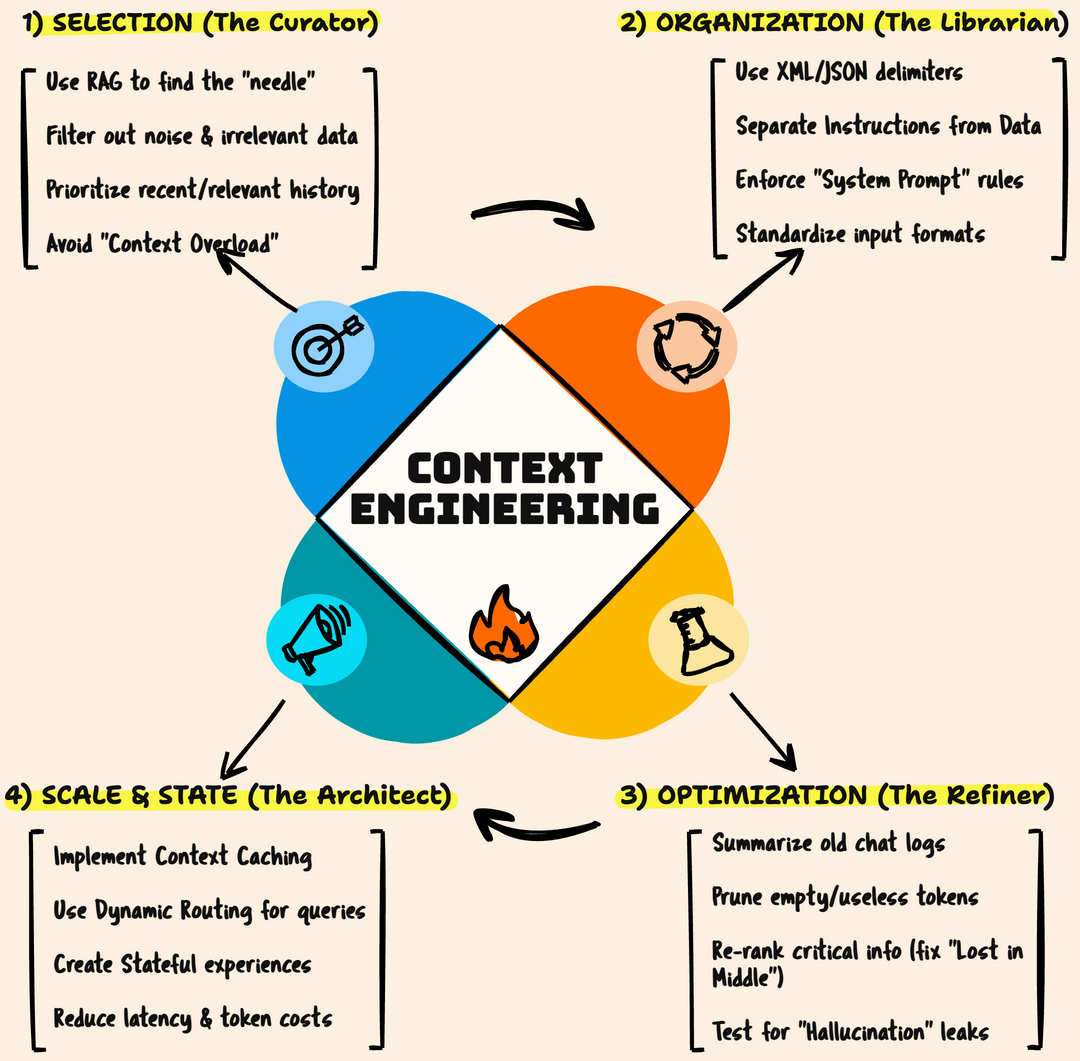
Here is the 4-step architectural loop for building that engine, based on the visual blueprint above.
Phase 1: Selection (The Curator)
- “Find the needle, don’t buy the haystack.”
The biggest mistake developers make is “Context Overload”. Instead of injecting a 50-page manual, sophisticated systems use RAG (Retrieval-Augmented Generation) to perform semantic searches. The goal is to identify the specific 3-5 paragraphs that are relevant to the user’s current intent and inject only those.
- The Rule: If it doesn’t answer the immediate question, filter it out.
Phase 2: Organization (The Librarian)
- “Structure is the language of reliability.”
A wall of text is hard for a model to parse. You need to use Structured Delimiters. By wrapping your context in XML tags (like <history>, <codebase>, <instructions> ), you clearly separate the “System Instructions” from the “User Data”. This prevents the model from getting confused about which part is the rule it needs to follow and which part is the data it needs to process.
Phase 3: Optimization (The Refiner)
- “Fix the attention span.”
This is where you solve the “Lost in the Middle” problem. You cannot treat all tokens equally. Advanced Context Engineering involves Re-ranking: algorithmically moving the most critical snippets of information to the end of the prompt (closest to the user’s question) to ensure the model pays attention to them. Simultaneously, you should be pruning empty tokens and summarizing old chat logs to keep the “signal-to-noise” ratio high.
Phase 4: Scale & State (The Architect)
- “Making the goldfish remember.”
The cutting edge of AI right now is moving from “Stateless” to “Stateful” experiences. New features like Context Caching (from Anthropic and Google) allow you to “upload” your massive documentation once and cache it. This drastically reduces latency and token costs, allowing you to query a massive knowledge base cheaply. Combined with Dynamic Routing —where a small router model decides which context to fetch based on query complexity—you have a system that scales.
The Verdict
The era of the “Prompt Engineer” tweaking adjectives is fading. The future belongs to the Context Architect.
Your model is smart enough. The bottleneck isn’t reasoning; it’s relevance. Stop asking better questions, and start engineering better answers.