While tech giants were locked in an arms race to build ever-larger models—each new release trumpeting billions more parameters than the last—a handful of researchers asked a heretical question: What if we’ve been thinking about this backwards?
What if bigger isn’t always better?
The answer shocked even those who had discovered it.
The Benchmark That Changed Everything
Let’s start with the numbers, because they’re almost too good to believe.
Microsoft’s Phi-3 Mini—a model with just 3.8 billion parameters—is matching GPT-3.5 on key reasoning tasks. Not “getting close.” Not “surprisingly good for its size.” Actually matching it.
Meta’s Llama 3 8B is handling complex question-answering, code generation, and summarization tasks that would’ve required GPT-4-class models just 18 months ago.
Google’s Gemma family is running sophisticated AI workloads on phones and laptops that previously needed server-farm infrastructure.
This isn’t an incremental improvement. This is a paradigm shift hiding in plain sight.
The models are 95% smaller. They run 15-20x cheaper. And somehow, they’re getting better results on real-world tasks than their massive predecessors from just two years ago.
Welcome to the SLM paradox.
Cracking the Code: Why Smaller Actually Works
Here’s what the researchers figured out, and it’s beautifully counterintuitive.
For years, we assumed the path to smarter AI was straightforward: more parameters + more data = better intelligence. Train on the entire internet, scale to trillions of parameters, and watch the magic happen.
But that approach had a hidden flaw. When you scrape the entire web, you’re not just getting high-quality content. You’re getting Reddit arguments, clickbait articles, spam blogs, and every piece of misinformation ever posted. Your model learns from the average of the internet—and the internet’s average quality is, well, average at best.
The breakthrough came from asking a different question: What if we trained on less data, but made it extremely high-quality?
Think of it like education. You could read 10,000 random books and come away confused, or you could read 100 carefully curated textbooks and become an expert. SLMs take the textbook approach.
The secret ingredients:
Curated datasets: Instead of scraping everything, researchers built “textbook-quality” datasets. Clean code repositories. Well-written technical documentation. Peer-reviewed papers. The stuff you’d actually want to learn from.
Knowledge distillation: Here’s where it gets clever. Take a massive, smart model (the “teacher”) and use it to train a tiny model (the “student”). The student doesn’t need to learn everything about the world—they just need to learn how to think like the teacher for specific tasks. It’s like an apprenticeship where you know the master’s techniques without needing their decades of experience.
Quantization magic: This is pure engineering brilliance. Traditional models store their “knowledge” in 32-bit floating-point numbers—incredibly precise but memory-hungry. Quantization compresses these down to 8-bit or even 4-bit integers. It’s like converting a RAW image to JPEG—you lose a tiny bit of fidelity that humans can’t notice, but the file shrinks by 75%.
The result? A 32GB model becomes 4GB. A data-center workload becomes a laptop task.
The Architecture Revolution: Rethinking How We Build
This shift isn’t just about swapping one model for another. Smart teams are redesigning their entire AI architecture around a new principle: intelligent routing.
The breakthrough insight is simple: not every task needs a supercomputer.
Summarizing an email? That’s straightforward. Drafting a five-page legal analysis citing obscure case law? That’s complex. Why pay cloud-model prices for both when you only need the horsepower for one?
Enter the hybrid pattern —and this is where things get really interesting.
Here’s how the new architecture works:
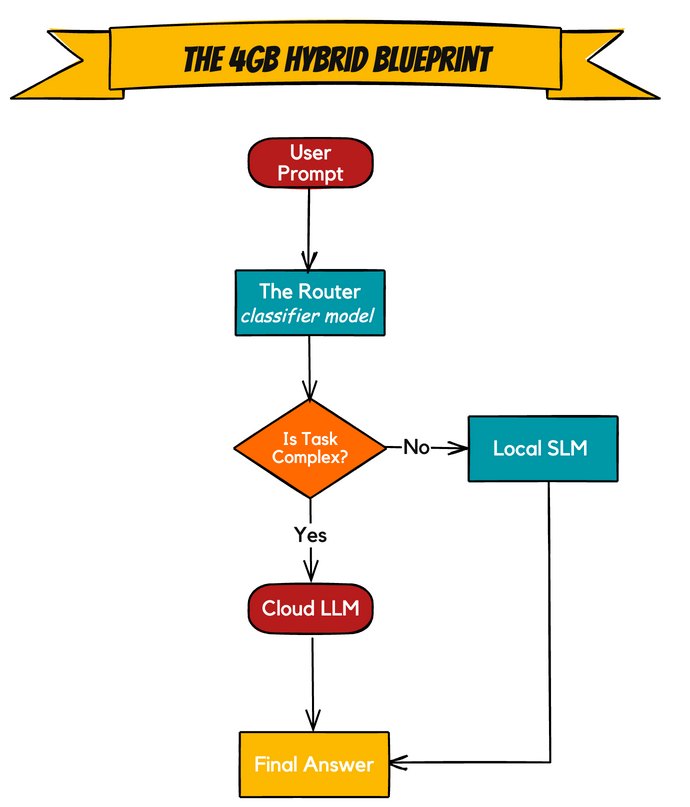
The Intelligence Layer: A small, fast classifier sits at the front of your system. It analyzes each incoming request and makes a split-second decision: simple or complex?
The Fast Lane: For 80% of queries—summaries, classifications, basic Q&A, data extraction—the request gets routed to your local SLM. Zero network latency. Zero cost. Complete privacy. The response comes back in milliseconds.
The Power Reserve: For the genuinely hard stuff—complex reasoning, creative writing, multi-step analysis—the system escalates to a cloud LLM. You pay for the compute, but only when you actually need it.
This isn’t compromise. It’s optimization. You’re getting the best of both worlds: the speed and privacy of edge AI for common tasks, with the raw power of cloud models as a safety net.
Some teams are reporting 90% cost reductions on their AI infrastructure while improving user experience because the local models respond so much faster.
The Unlock: What This Actually Enables
Let’s talk about what becomes possible when you can run serious AI on consumer hardware.
Privacy by Design
Imagine you’re building a medical app that analyzes patient notes. Or a legal tool that summarizes contracts. Or a financial advisor that processes transaction history.
Under the old cloud-first model, every piece of sensitive data had to leave your user’s device, traverse the internet, get processed on someone else’s server, and come back. For regulated industries, this was often a non-starter.
With SLMs, the entire workflow happens locally. The data never leaves the device. For healthcare, finance, and legal tech, this isn’t just a feature—it’s the difference between “impossible to deploy” and “ready for production.”
Real-Time Everything
Network round-trips take time. Sometimes hundreds of milliseconds. For most apps, that’s fine. For gaming, AR/VR, live translation, or interactive UI, it’s a dealbreaker.
Local inference is instant. The model lives on the same device as your application. There’s no queueing, no network variability, no “waiting for response” spinner. This unlocks an entire class of real-time AI features that simply weren’t possible before.
Offline-First Intelligence
Your Wi-Fi is down. You’re on a plane. You’re in a tunnel. Under the cloud-first paradigm, your AI features just… stop working.
With edge AI, your application stays smart everywhere. The intelligence lives on the device. This is huge for mobile apps, field service tools, and any use case where connectivity is unreliable.
The Economics Flip
Let’s run some numbers. A typical GPT-4 API call costs about $0.03 per 1,000 tokens. If your app makes a million requests per month, that’s roughly $30,000 in compute costs—and that’s assuming relatively small prompts.
Running Llama 3 8B locally? After the one-time cost of downloading the model (free), every inference is essentially free. No per-token pricing. No rate limits. No surprise bills.
For startups and indie developers, this changes the equation entirely. You can build sophisticated AI features without worrying about usage-based pricing that scales faster than your revenue.
The Honest Truth: Where SLMs Still Struggle
Let’s pump the brakes for a moment and talk about reality.
SLMs are powerful, but they’re not magic. They’re specialists, not generalists. Understanding their limitations is just as important as understanding their strengths.
Limited World Knowledge
Ask an 8B parameter model about a specific historical event, or an obscure scientific concept, or a niche cultural reference, and it might come up empty. These models simply don’t have the “storage capacity” for comprehensive world knowledge.
Think of it like the difference between a general practitioner and a specialist. The GP knows a little about everything. The specialist knows a lot about their specific domain. SLMs are specialists.
Complex Multi-Step Reasoning
On benchmarks like MMLU (Massive Multitask Language Understanding), SLMs still trail the giants. If your application requires deep, multi-step logical deduction—complex legal reasoning, advanced mathematics, intricate strategic planning—you’ll still need the big cloud models.
The key is knowing which tool for which job. And increasingly, that’s what the hybrid architecture solves.
Your Developer Moment: The Toolkit Is Ready
Here’s the exciting part: you don’t need a research lab or a PhD to start building with SLMs. The ecosystem has matured incredibly fast, and the barriers to entry have collapsed.
The Tools:
Ollama is your easiest starting point. Think of it as Docker for language models. One command— ollama run phi3 —and you’ve got a fully functional local AI API running on your machine. It handles model downloads, memory management, and inference optimization automatically.
llama.cpp is the engine under the hood of this entire revolution. It’s a highly optimized C++ implementation that lets these models run blazingly fast on standard CPUs. No massive GPU required. This is the hardcore tool for when you need maximum control and performance.
MLX is Apple’s gift to Mac developers. It’s specifically designed to leverage the unified memory architecture of Apple Silicon chips, making MacBooks surprisingly powerful AI development machines. If you’re on an M-series Mac, this is your secret weapon.
The hardware requirements? More accessible than you’d think. Llama 3 8B (quantized to INT4) needs about 5.3GB of VRAM. That means it runs comfortably on an entry-level gaming laptop with an RTX 3060, or any M1/M2/M3 MacBook.
This is AI infrastructure that fits in a backpack.
The Future Is Already Here
Here’s what’s happening right now, while everyone’s still debating whether AGI is five or fifty years away:
A medical startup is running HIPAA-compliant patient note analysis entirely on local devices. A legal tech company is processing confidential contracts without any data leaving the firm’s network. A gaming studio is building NPCs with dynamic dialogue that responds in real-time with zero latency.
None of this was possible two years ago.
The shift isn’t coming. It’s already underway. The question is whether you’re building for the old paradigm or the new one.
Cloud models aren’t disappearing—we’ll always need them for the hardest problems. But the future isn’t only massive centralized intelligence. It’s a distributed swarm of billions of specialized AIs running everywhere—in our pockets, on our desks, in our cars, embedded in devices we haven’t imagined yet.
The paradox resolved itself: AI didn’t get smarter by getting bigger. It got smarter by learning to be precisely the right size for the job at hand.
The 4GB revolution is here. The tools are ready. The architecture patterns are proven.
Now it’s your turn. What will you build when you own the model?